오늘 가져온 논문은 RSS 2024 (Robotics: Science and Systems) 등록된(?) 논문이다.
Robotics에서 Imitation Learning 을 다루고 있고 제목에서 알 수 있듯이 3D 즉, 3차원 정보를 갖고 Diffusion policy를 적용한 모델이다.
Imitation Learing은 효과적으로 dexterous skills를 학습할 수 있지만 복잡하고 generalizable 을 갖기 위해서 일반적으로 많은양의 human demonstrations가 필요하다고 한다. 많은 양의 expert data는 데이터를 만드는 비용이 큰데 이 문제를 해결하기 위해서 한가지 방법으로 Online learning을 이용하는 방식이 있다. 하지만 Online learning도 문제가 있는데 safety problem, the neccessity for automatic ressetting, human intervention, robot hardware cost 등이 있다.
본 논문에서는 이 문제를 해결하기 위해 3D Diffusion Policy (DP3)를 소개하였고 2D 이미지를 사용하는 것이 아닌 3D visual representations를 이용해 사용했다고 한다.
DP3 이전에는 Diffusion Policy 논문이 있는데, 로봇의 trajectory에 noise를 주면서 policy를 denoising 과정을 통해 뽑아내는 모델이다. DP3의 핵심은 3D representation 이라할 수 있다.
2D-based diffusion policy, baselines과 비교해서 차이점이 뭔데?
- Efficiency & Effectiveness : fewer demonstrations, fewer training steps만 가지고도 좋은 성능을 가진다고 한다.
- Generalizability : space, view point, instance, appearance에 대해 일반화 능력이 좋다고 한다. 이것에 대해서는 모델 input data를 처리하는 과정을 보면 이유를 알 수 있다.
- Safe depolyment : real-world tasks 에 대해 erratic commands를 발생할 확률이 적다고 한다.
- 이러한 관측 결과에 대한 이유는 논문에서도 이론적으로 이유를 밝혀내진 못했다.
- future work로 남겨두었지만 이것에 대해 이론적인 이유를 찾아낸다면 online learning에서도 좋을 것 같다.
기존 3D representation Visual Imitation Learning
3DP를 말고도 다양한 논문에서 3D representation 을 이용한 모델이 있다. PerAct, GNFactor, RVT, ACT3D, NeRFuser, 3D Diffuser Actor에서 low-dimensional control tasks에 대해 좋은 성능을 보였다. 하지만 high-dimensional control task에서는 not suitable하고 inference속도가 느린 문제가 있다고한다. 여기서 말하는 dimensional control task는 제어해야 할 state, action space를 나타낸다. 3DP에서는 앞선 문제를 개선했다고 한다.

DP3는 위 구조에서 볼 수 있듯이 크게 두 부분으로 나눠진다.
Perception
Perception 단계에서는 현재 environment를 이해하는 단계로 환경을 전처리하는 단계이다. DP3는 single-view camera를 통해 84 x 84 depth image를 받는다. 특이한점으로는 generalization를 위해 color channels를 사용하지 않고 오로지 depth를 이용했다. 3D representation을 이용하는 방식은 다양한데 RGBD, point clouds, voxels, implicit functions, 3D gaussians 등이 있고 해당 모델에서는 point cloud를 사용했다. 실험결과를 확인해보면 다양한 방식으로도 테스트를 해보았고 point cloud 방식이 가장 좋게 나온것을 확인 할 수 있었다. 그렇게 받아온 depth image를 point cloud로 변환하고 redundant points를 제거하기 위해 bounding box를 통해 crop해서 사용하였다. (code를 확인해본 결과 center crop과 같은 느낌으로 crop을 진행하였다.) 그 이후 farthest point sampling (FPS)를 통해 downsample하고 LayerNorm을 적용한 MLP 3개 층을 통해 전처리를 하고 64차원 데이터를 뽑아낸다.
카메라는 realsense L515 ( ₩1,041,280 )를 사용하였고 카메라 성능에 따라 모델 성능이 달라질 수 있다고 한다.
Decision
Perception 과정을 통해 뽑아온 3D visual features (v) 와 robot poses (q) 를 input으로 사용하고 diffusion을 적용해 action (a) 를 Gaussian noising과 denoising하는 과정을 통해 뽑는다.

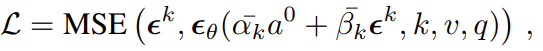
implementation details 로 diffusion policy를 base로 convolutional network를 사용했고 noise scheduler로 DDIM을 사용했다고 한다. Decision부분에서는 크게 특별한 부분은 없는것 같다.

실험에서는 72개의 simulation tasks에서 좋은 성능을 보였다. 아쉬운 점은 competitive inference speed를 장점으로 적혀있지만 다른 모델과 비교해서 얼마나 빠른 것인지 수치적으로 나와있지는 않은 것 같다.
마치며...
3D representation 을 통한 로봇제어에 관심있어 읽어본 논문이지만 막상 읽어보니 흥미를 이끌만한 크게 특별한점은 없는 것 같다. representation 에대해 좀 더 다양하게 공부를 해봐야할 것 같다.
기술발전이 빠르다보니 요새는 확실히 기존 있던 기술을 얼마나 알맞게 쓰는지에 대한 논문이 많은 것 같다.
읽다보면 뭔가 나도 할 수 있을 것 같은 자신감이 생기는 느낌 .. .
재밌는 논문을 좀 찾아봐야겠다. 강화학습?쪽으로 새로운 모델이 있는지 찾아봐야겠다.